Современный русский алфавит, его происхождение и краткая история.
Алфавит [греч. аlphábētos
< названия первых двух букв греч.
алфавита – α ‘альфа’ и β
‘бета/вита’] — упорядоченная совокупность
основных знаков письма – букв (см.).
Русский алфавит называют также а з б у
к о й [от названия первых двух букв
кириллицы – а ‘аз’ и б ‘буки’;
калька с греч.]. Термин азбука
встречается в русских текстах с XIII в.,
а прямое заимствование алфавит –
с XV в.
Понятие алфавита включает как минимум
следующие признаки: 1) буквенный
состав, 2) порядок букв, 3) начертания
и 4) названия букв.
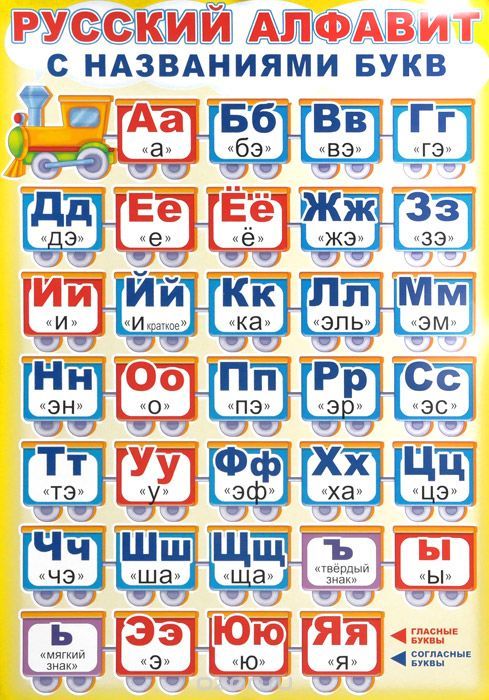
Современный русский алфавит насчитывает
33 буквы (см. также Буква Ё), которые
располагаются в строго определенном
порядке от а до я. Без
знания буквенного состава алфавита и
начертаний букв невозможен сам процесс
письма и чтения, а знание порядка букв
в алфавите необходимо для пользования
словарями, справочниками, различными
каталогами, где информация расположена
в строгом алфавитном порядке. Знание
Знание
названий букв
в большинстве случаев помогает при
чтении аббревиатур (например, МЧС:
ср. нормативное [эмчеэс] и ненормативное
[эмчаэс]), хотя строгого правила
ориентироваться на официальное название
буквы нет (ср. нормативные варианты ФРГ
[фээргэ] и [эфэргэ]), и при этом наряду со
знанием строгого алфавитного порядка
букв является одним из важных показателей
культуры речи как существенной части
общей культуры человека. Названия
некоторых букв имеют варианты, например:
й – «и краткое» и «ий», э – «э»
и «э оборотное». У буквы л наряду с
традиционным названием «эль» появился
почти официальный вариант «эл», возникший
в результате выравнивания «нестандартного»
названия буквы «эль» по типу букв «эн»,
«эм», «эс», «эр», «эф». В то же время в
просторечии имеют место попытки выровнять
названия букв «эл(ь)», «эн», «эм», «эс»,
«эр», «эф» по типу названий букв «бэ»,
«вэ», «гэ», однако названия «лэ», «нэ»,
«мэ», «сэ», «рэ», «фэ» не являются
нормативными.
Правописание названий букв официальными
правилами русской орфографии строго
не регламентировано: например, при
предпочтительном, подсказывающем
произношение, написании бэ, вэ, жэ, цэ
и т. п. встречаются (в т. ч. и в
п. встречаются (в т. ч. и в
толковых словарях русского языка)
написания бе, ве, же, це и т. п.
Современные названия букв, за исключением
твердого и мягкого знаков, являются
несклоняемыми существительными среднего
рода: ср. прописное А, строчное б,
написано лишнее н и т. п. Такие
названия (а, бэ, вэ и т. д.) появились
в XVIII в. под влиянием латинского
алфавита и полностью вытеснили старые
церковнославянские имена букв (аз,
буки, веди и т. д.) в XX в. Некоторые
из старых названий букв сохраняются в
устойчивых выражениях, например: ни
аза не знает ‘ничего не знает’, стоять
фертом ‘подбоченясь, c
самодовольным видом’ и т. п.
Буквы алфавита предназначены для того,
чтобы обозначать на письме звуки речи.
Если исходить из того, что количество
гласных звуков должно совпадать с
количеством гласных букв, а с состав
согласных звуков – с составом согласных
букв звуков русского языка, обнаружится,
что современный алфавит не удовлетворяет
этому требованию, поскольку, во-первых,
в нем не хватает букв для обозначения
парных мягких согласных фонем, а
во-вторых, имеется некоторый избыток
букв для гласных: на 6 гласных звуков
приходится 10 букв. Такое положение
Такое положение
возникло исторически, в результате
звуковых изменений, которые произошли
в русском языке, однако русское письмо
регулирует дисбаланс между буквами и
звуками с помощью слогового принципа
графики (см.).
Современный русский алфавит представляет
собой развитие древней славянской
кириллицы (см.). В процессе исторического
развития на русской почве в кириллице
произошли существенные изменения в
составе (современный алфавит почти на
четверть меньше по сравнению с
первоначальной кириллицей (см. История
русского алфавита), но пополнился
тремя новыми буквами э, й, ё),
начертаниях (кардинальные изменения
произошли в период петровской реформы
графики), и названиях букв (процесс
начался в XVIII и в целом завершился в
XX в.), а также в их звуковых значениях
(это результат звуковых изменений на
протяжении всей письменной истории
русского языка).
toPhonetics
Привет! Мы хотим сделать этот онлайн-переводчик английского текста в транскрипцию самым лучшим в Интернете (подробнее о проекте). Свои пожелания и отзывы оставляйте в комментариях ниже, они обязательно будут учтены. Ответы на часто задаваемые вопросы здесь.
Свои пожелания и отзывы оставляйте в комментариях ниже, они обязательно будут учтены. Ответы на часто задаваемые вопросы здесь.
Транскриптор имеет следующие особенности и функции:
- Британский или американский вариант произношения слов. При выборе британского диалекта, в соответствии с британской фонетикой [r] в конце слова озвучивается, только если следующее слово во фразе начинается с гласного звука.
- Привычные нам символы международного фонетического алфавита (IPA).
- Транскрипция текста сохраняет исходный формат предложений, включая знаки препинания и т.п.
- Возможность отображения транскрипции с учётом слабой позиции слов в предложении, как это происходит в живой связной речи (галочка “Учитывать слабую позицию”).
- Не найденные слова, набранные в верхнем регистре, интерпретируются как аббревиатуры (транскрипция аббревиатур отображается побуквенно через дефис).
- Чтобы удобнее было сверяться с оригиналом, возможен параллельный вывод транскрипции в два столбца с исходным английским текстом или подстрочником.
 Просто укажите нужный вариант под полем ввода.
Просто укажите нужный вариант под полем ввода. - Нужен английский текст песни русскими буквами? Пожалуйста! Рядом с полем ввода есть соответствующая галочка для тех, кто никогда не учил английский (тем не менее, фонетическая транскрипция несложна в освоении и всегда предпочтительнее).
- В случаях, когда слово может произноситься по-разному, вы можете выбрать из нескольких вариантов транскрипции. Такие слова отображаются в виде ссылок (синим цветом). Если навести на них мышь, то появится список вариантов произношения. Для перебора вариантов в тексте (чтобы потом распечатать или скопировать текст в буфер обмена с правильным произношением) нужно щёлкнуть по слову мышью.
Имейте в виду, что несколько вариантов транскрипции может отражать как вариации произношения в одном значении, так и произношение разных значений слова. Если вы не уверены, какой вариант нужен в вашем случае, сверьтесь со словарём. - Кроме общеупотребительных слов словарная база включает транскрипцию огромного количества географических названий (среди которых названия стран, их столиц, штатов США, графств Англии), а так же национальностей и наиболее популярных имён.
- Ненайденные слова (показываются красным цветом) регистрируются, и в случае повторения в запросах регулярно добавляются в словарную базу.
- Если ваш браузер поддерживает синтез речи (Safari – рекомендуется, Chrome), вы можете прослушать транскрибируемый текст. Подробности по ссылке.
- Вместо кнопки “Показать транскрипцию” можно использовать комбинацию клавиш Ctrl+Enter из поля ввода.
- Доступны также мобильные версии сервиса для устройств Apple и Андроид.
 Просто укажите нужный вариант под полем ввода.
Просто укажите нужный вариант под полем ввода.
Если при копировании на свой компьютер символы IPA отображаются у вас некорректно, значит у вас проблема со шрифтами. Прочитайте “Техническое примечание” внизу этой страницы на Википедии. Шрифты с поддержкой IPA можно найти здесь.
Русская кириллица – Etsy.de
Etsy больше не поддерживает старые версии вашего веб-браузера, чтобы обеспечить безопасность пользовательских данных. Пожалуйста, обновите до последней версии.
Воспользуйтесь всеми преимуществами нашего сайта, включив JavaScript.
Найдите что-нибудь памятное,
присоединяйтесь к сообществу, делающему добро.
(618 релевантных результатов)
Кодировка
– Почему команда Windows DIR выдает ??? символы вместо русского алфавита?
Задать вопрос
спросил
Изменено
2 года, 6 месяцев назад
Просмотрено
2к раз
В окне Windows 10 через командную строку я запускаю эту команду:
C:\Users\idiot\Music>dir /a:d /s /b >> tom-music-2016-july. txt
txt
Цель состоит в том, чтобы перечислить все каталоги. Но я замечаю, что каталоги с нелатинскими буквами в названии будут печатать ????? вместо русских или китайских иероглифов. Почему?
Изначально я думал, что проблема в системных шрифтах. (У меня не установлен русский языковой пакет). Но я могу переименовывать файлы в русские имена файлов в Win Explorer. Важно то, что когда я запускаю команду DIR в окне (без конвейера в выходной файл), я четко вижу русские символы .
Это означает, что проблема либо с командой, которая передает что-то в файл, либо с текстовым редактором Windows, который пытается прочитать вывод.
Я пытался открыть файл в двух разных текстовых редакторах и даже в веб-браузере, но все равно вижу знаки вопроса.
Кто-нибудь может предложить причину этой проблемы и возможное решение?
Правильно ли я предполагаю, что мне не нужно будет выполнять какую-либо обработку самих файлов или каталогов? Спасибо.
Постскриптум: Меня особенно озадачило то, почему русские символы нормально отображаются в окне консоли, но когда они передаются в файл, я вижу вопросительные знаки.
- windows-10
- кодировка
- каталог
3
Ничего секретного: кодирование файла, созданного с использованием перенаправления > , соответствует текущей активной кодовой странице cmd . ? (знак вопроса) — это просто замена (маркер замены), если символ не существует в такой кодовой странице.
Решение: используйте UTF-8 (кодовая страница 65001) как chcp 65001
Следующий пример иллюстрирует ( и, возможно, доказывает ) это достаточно хорошо: 1250
Активная кодовая страница: 1250
d:\bat\Имена UnASCII> dir /b /AD >dir1250.txt
d:\bat\Имена UnASCII> chcp 65001
Активная кодовая страница: 65001
d:\bat\Имена UnASCII> dir /b /AD >dir65001.